Part 2: distributed computing with Ray
June 13th
9:30am–12:30pm and 1:30pm-4:30pm Pacific Time
There is a number of high-level open-source parallel frameworks for Python that are quite popular in data science and beyond:
- Ray is a unified framework for scaling AI and Python applications.
- Dask parallelizes Python loops and graphs of functions, scales NumPy, pandas, and scikit-learn.
- PySpark is the Python API for Apache Spark for large-scale data processing in a distributed environment.
- Mars is a tensor-based unified framework for large-scale data computation which scales NumPy, pandas, scikit-learn and many other libraries.
- mpi4py is the most popular Message Passing Interface (MPI) implementation for Python.
- IPyParallel architecture for parallel and distributed computing.
- Joblib for parallel for loops with multiprocessing.
Here we’ll focus on Ray, a unified framework for scaling AI and general Python workflows. Since this is not a machine learning workshop, we will not touch Ray’s AI capabilities, but will focus on its core distributed runtime and data libraries. We will learn several different approaches to parallelizing purely numerical (and therefore CPU-bound) workflows, both with and without reduction. We will also look at I/O-bound workflows.
Initializing Ray
import ray
ray.init() # start a Ray cluster and connect to it
# no longer necessary, will run by default when you first use it
However, ray.init() is very useful for passing options at initialization. For example, Ray is quite verbose
when you do things in it. To turn off this logging output to the terminal, you can do
ray.init(configure_logging=False) # hide Ray's copious logging output
You can run ray.init() only once. If you want to re-run it, first you need to run
ray.shutdown(). Alternatively, you can pass the argument ignore_reinit_error=True to the call.
You can specify the number of cores for Ray to use, and you can combine multiple options, e.g.
ray.init(num_cpus=4, configure_logging=False)
By default Ray will use all available CPU cores, e.g. on my laptop ray.init() will start 8 ray::IDLE
processes (workers), and you can monitor these in a separate shell with htop --filter "ray::IDLE" command
(you may want to hide threads – typically thrown in green – with Shift+H).
Discussion
How many “ray::IDLE” processes do you see, and why? Recall that you can use
srun --jobid=<jobID> --pty bashto open an interactive shell process inside your currently running job, and runhtop --filter "ray::IDLE"there.
Question 11
How would you pass the actual number of processor cores to the Ray cluster? Consider three options:
- Using a Slurm environment variable. How would you pass it to
ray.init()? - Launching a single-node Ray cluster as described in our Ray documentation.
- Not passing anything at all, in which case Ray will try – unsuccessfully – to grab all cores.
Ray tasks
In Ray you can execute any Python function asynchronously on separate workers. Such functions are called Ray remote functions, and their asynchronous invocations are called Ray tasks:
import ray
ray.init(configure_logging=False) # optional
@ray.remote # declare that we want to run this function remotely
def square(x):
return x * x
r = square.remote(10) # launch/schedule a remote calculation (non-blocking call)
type(r) # ray._raylet.ObjectRef (object reference)
ray.get(r) # retrieve the result (=100) (blocking call)
The calculation may happen any time between <function>.remote() and ray.get() calls, i.e. it does not
necessarily start when you launch it. This is called lazy execution: the operation is often executed when
you try to access the result.
a = square.remote(10) # launch a remote calculation
ray.cancel(a) # cancel it
ray.get(a) # either error or 100, depending on whether the calculation
# has finished before cancellation
You can launch several Ray tasks at once, to be executed in parallel in the background, and you can retrieve their results either individually or through the list:
r = [square.remote(i) for i in range(4)] # launch four parallel tasks (non-blocking call)
print([ray.get(r[i]) for i in range(4)]) # retrieve the results (multiple blocking calls)
print(ray.get(r)) # more compact way to do the same (single blocking call)
Task output
Consider a code in which each Ray task sleeps for 10 seconds, prints a message and returns its task ID:
import ray
from time import sleep, time
ray.init(num_cpus=4, configure_logging=False)
@ray.remote
def nap():
sleep(10)
print("almost done")
return ray.get_runtime_context().get_task_id()
Let’s run it with timing on:
start = time()
r = [nap.remote() for i in range(4)]
ray.get(r)
end = time()
print("Time in seconds:", round(end-start,3))
I get 10.013 seconds since I have enough cores to run all of them in parallel. However, most likely, I see
printout (“almost done”) from only one process and a message “repeated 3x across cluster”. To enable print
messages from all tasks, you need set the bash shell environment variable export RAY_DEDUP_LOGS=0.
Notice that Ray task IDs are not integers but 48-character hexadecimal numbers.
Distributed progress bars
from ray.experimental.tqdm_ray import tqdm
@ray.remote
def busy(name):
if "2" in name: sleep(2)
for x in tqdm(range(100), desc=name):
sleep(0.1)
[busy.remote("task 1"), busy.remote("task 2")]
A side effect of tqdm() is that these tasks start running immediately.
Question 11b
Implement the same for 10 tasks using afor loop.
Note: Ray’s
tqdm()is somewhat buggy, so you might want to restart Python and your Ray cluster, if you don’t want to see artifacts from previous bars sometimes popping up in your session.
Parallelizing the slow series with Ray tasks
Let’s perform our slow series calculation as a Ray task. This is our original serial implementation, now with a Ray remote function running on one of the workers:
from time import time
import ray
ray.init(num_cpus=4, configure_logging=False)
@ray.remote
def slow(n: int):
total = 0
for i in range(1,n+1):
if not "9" in str(i):
total += 1.0 / i
return total
start = time()
r = slow.remote(100_000_000)
total = ray.get(r)
end = time()
print("Time in seconds:", round(end-start,3))
print(total)
We should get the same timing as before (~6-7 seconds). You can call ray.get() on the previously computed
result again without having to redo the calculation:
start = time()
tmp = ray.get(r)
end = time()
print("Time in seconds:", round(end-start,3)) # 0.001 seconds
print(tmp)
Let’s speed up this calculation with parallel Ray tasks! Instead of doing the full sum over range(1,n+1),
let’s calculate a partial sum on each task:
from time import time
import psutil, ray
ray.init(num_cpus=4, configure_logging=False)
@ray.remote
def slow(interval):
total = 0
for i in range(interval[0],interval[1]+1):
if not "9" in str(i):
total += 1.0 / i
return total
This would be a serial calculation:
n = 100_000_000
start = time()
r = slow.remote((1, n)) # takes in one argument
total = ray.get(r)
end = time()
print("Time in seconds:", round(end-start,3))
print(total)
To launch it in parallel, we need to subdivide the interval:
ncores = psutil.cpu_count(logical=False) # good option on a standalone computer
ncores = 4 # on a cluster
size = n//ncores # size of each batch
intervals = [(i*size+1,(i+1)*size) for i in range(ncores)]
if n > intervals[-1][1]: intervals[-1] = (intervals[-1][0], n) # add the remainder (if any)
start = time()
r = [slow.remote(intervals[i]) for i in range(ncores)]
total = sum(ray.get(r)) # compute total sum
end = time()
print("Time in seconds:", round(end-start,3))
print(total)
On 8 cores I get the average runtime of 1.282 seconds – not too bad, considering that some of the cores are low-efficiency (slower) cores.
Question 12
Increasen to 1_000_000_000 and run htop --filter "ray::IDLE in a separate shell to monitor CPU usage of
individual processes.
Running Numba-compiled functions as Ray tasks
We ended Part 1 with a Numba-compiled version of the slow series code that works almost as well as a Julia/Chapel code. As you just saw, Ray itself can distribute the calculation, speeding up the code with parallel execution, but individual tasks still run native Python code that is slow.
Wouldn’t it be great if we could use Ray to distribute execution of Numba-compiled functions to workers? It
turns out we can, but we have to be careful with syntax. We would need to define remote compiled functions,
but neither Ray, nor Numba let you combine their decorators (@ray.remote and @numba.jit, respectively) for
a single function. You can do this in two steps:
import ray
from numba import jit
ray.init(num_cpus=4, configure_logging=False)
@jit(nopython=True)
def square(x):
return x*x
@ray.remote
def runCompiled():
return square(5)
r = runCompiled.remote()
ray.get(r)
Here we “jit” the function on the main process and send it to workers for execution. Alternatively, you can “jit” on workers:
import ray
from numba import jit
ray.init(num_cpus=4, configure_logging=False)
def square(x):
return x*x
@ray.remote
def runCompiled():
compiledSquare = jit(square)
return compiledSquare(5)
r = runCompiled.remote()
ray.get(r)
In my tests with more CPU-intensive functions, both versions produce equivalent runtimes.
Question 13: combining Numba and Ray remotes for the slow series (big one!)
Write a slow series solver with Numba-compiled functions executed as Ray tasks.
- Numba-compiled
combined(k)that returns either 1/x or 0. - Numba-compiled
slow(interval)for partial sums. - Ray-enabled remote function
runCompiled(interval)to launch partial sums on workers. - Very important step: you must do small
runCompiled()runs on workers to copy code over to them – no need to time these runs. Without this “pre-compilation” step you will not get fast execution on workers on the bigger problem. - The rest of the code will look familiar:
start = time()
r = [runCompiled.remote(intervals[i]) for i in range(ncores)]
total = sum(ray.get(r)) # compute total sum
end = time()
print("Time in seconds:", round(end-start,3))
print(total)
Averaged (over three runs) times:
| ncores | 1 | 2 | 4 | 8 |
| wallclock runtime (sec) | 0.439 | 0.235 | 0.130 | 0.098 |
Using a combination of Numba and Ray tasks on 8 cores, we accelerated the calculation by ~68X.
Getting partial results from Ray tasks
Consider the following code:
from time import sleep
import ray, random
@ray.remote
def longSleep():
duration = random.randint(1,100) # random integer from [1,100]
sleep(duration) # sleep for this number of seconds
return f"I slept for {duration} seconds"
refs = [longSleep.remote() for x in range(1,21)] # start 20 tasks
If we now call ray.get(refs), that would block until all of these remote tasks finish. If we want to, let’s
say, one of them to finish and then continue on the main task, we can do:
ready_refs, remaining_refs = ray.wait(refs, num_returns=1, timeout=None) # wait for one of them to finish
print(ready_refs, remaining_refs) # print the IDs of the finished task, and the other 19 IDs
ray.get(ready_refs) # get finished results
Let’s wait for the first 5 answers:
ready_refs, remaining_refs = ray.wait(refs, num_returns=5, timeout=None) # wait for 5 of them to finish
ray.get(ready_refs) # get finished results
for i in remaining_refs:
ray.cancel(i) # cancel the unfinished ones
Multiple returns from Ray tasks
Similar to normal Python functions, Ray tasks can return tuples:
import ray
@ray.remote
def threeNumbers():
return 10, 20, 30
r = threeNumbers.remote()
print(ray.get(r)[0]) # get the result (tuple) and show its first element
Alternatively, you can pipe each number to a separate object ref (tell the decorator!):
@ray.remote(num_returns=3)
def threeNumbers():
return 10, 20, 30
r1, r2, r3 = threeNumbers.remote()
ray.get(r1) # get the first result only
You can also create a remote generator that will return only one number at a time, to reduce memory usage:
@ray.remote(num_returns=3)
def threeNumbers():
for i in range(3): # should return 10,20,30
yield (i+1)*10
r1, r2, r3 = threeNumbers.remote()
ray.get(r1) # get the first number only
Linking remote tasks
In addition to values, object refs can also be passed to remote functions. Define two functions:
import ray
@ray.remote
def one():
return 1
@ray.remote
def increment(value):
return value + 1
In by-now familiar syntax:
r1 = one.remote() # create the first Ray task
r2 = increment.remote(ray.get(r1)) # pass its result as an argument to another Ray task
print(ray.get(r2))
You can also shorten this syntax:
r1 = one.remote() # create the first Ray task
r2 = increment.remote(r1) # pass its object ref as an argument to another Ray task
print(ray.get(r2))
As the second task depends on the output of the first task, Ray will not execute the second task until the first task has finished.
Persistent storage on Ray workers
You might have noticed that Ray functions (remote tasks) are stateless, i.e. they can run on any processor that happens to be more idle at the time, and they do not store any data on that processor in between the function calls.
If you are trying to parallelize a tightly-coupled problem, you might want to store arrays on the workers permanently, and then repeatedly call quick functions to do some computations on these arrays, without copying the arrays back and forth at each step.
To do this in Ray, we can use Ray actors (https://docs.ray.io/en/latest/ray-core/actors.html). A Ray actor is essentially a stateful (bound to a processor) worker that is created via a Python class instance with its own persistent variables and methods, and it stays permanently on that worker until we destroy this instance.
import ray
import numpy as np
ray.init()
@ray.remote
class ArrayStorage: # define an actor (ArrayStorage class) with a persistent array
def __init__(self):
self.array = None # persistent array variable
def store_array(self, arr):
self.array = arr # store an array in the actor's state
def get_array(self):
return self.array # retrieve the stored array
storage_actor = ArrayStorage.remote() # create an instance of the actor
arr = np.array([1, 2, 3, 4, 5])
ray.get(storage_actor.store_array.remote(arr)) # store an array
r = ray.get(storage_actor.get_array.remote()) # retrieve the stored array
print(r) # Output: [1 2 3 4 5]
To scale this to multiple workers, we can do the same with an array of workers:
workers = [ArrayStorage.remote() for i in range(2)] # create two instances of the actor
r = [workers[i].store_array.remote(np.ones(5)*(i+1)) for i in range(2)]
print(ray.get(r))
print(ray.get(workers[0].get_array.remote())) # [1. 1. 1. 1. 1.]
print(ray.get(workers[1].get_array.remote())) # [2. 2. 2. 2. 2.]
r = [workers[i].get_array.remote() for i in range(2)]
print(ray.get(r)) # both arrays in one go
If we want to make sure that these arrays stay on the same workers, we can retrieve and print their IDs and the node IDs by adding these two functions to the actor class:
...
def get_actor_id(self):
return self.actor_id
def get_node_id(self):
return self.node_id # the node ID where this actor is running
...
print([ray.get(workers[i].get_actor_id.remote()) for i in range(2)]) # actor IDs
print([ray.get(workers[i].get_node_id.remote()) for i in range(2)]) # node IDs
You can even use NumPy on workers. For example, if we were to implement a linear algebra solver on a worker and wanted to have the solution array stored there permanently, we could do it this way:
import numpy as np
import ray
ray.init(num_cpus=2, configure_logging=False)
n = 500
h = 1/(n+1)
b = np.exp(-(100*(np.linspace(0,1,n)-0.45))**2)*h*h
@ray.remote
class ArrayStorage:
def __init__(self, n):
self.b = None # persistent variable
self.u = None # persistent variable
flatIdentity = np.identity(n).reshape([n*n])
a = -2.0*flatIdentity
a[1:n*n-1] = a[1:n*n-1] + flatIdentity[:n*n-2] + flatIdentity[2:]
self.a = a.reshape([n,n]) # persistent variable
def store_b(self, arr):
self.b = arr # store an array in the actor's state
def get_u(self):
return self.u
def localSolve(self):
self.u = np.linalg.solve(self.a,self.b)
worker = ArrayStorage.remote(n)
worker.store_b.remote(b)
worker.localSolve.remote()
u = ray.get(worker.get_u.remote())
print("The solution is", u)
Finally, you can delete a Ray actor with:
ray.kill(worker)
Is it possible to use JIT-compiled functions inside a Ray actor? The answer is “probably yes”: in Numba there is an experimental feature to compile Python classes with
@jitclass. Whether you can use it to compile Ray classes is an open question – I’d be very interested to hear your findings on this.
Ray Data
Ray Data is a parallel data processing library for ML workflows. As you will see in this section, Ray Data can be easily used for non-ML workflows. To process large datasets, Ray Data uses streaming/lazy execution, i.e. processing does not happen until you try to access (“consume” in Ray’s language) the result.
The core object in Ray Data is a dataset which is a distributed data collection. Ray datasets can store general multidimensional array data that are too large to fit into a single machine’s memory. In Ray, these large arrays will be:
- distributed in memory across a number of Ray tasks and
- saved to disk once they are no longer in use.
Ray’s dataset operates over a sequence of Ray object references to blocks. Each block contains a disjoint subset of rows, and Ray Data loads and transforms these blocks in parallel. Each row in Ray’s datasets is a dictionary.
Recall: a Python dictionary is a collection of key-value pairs.
Creating datasets
import ray
ray.init(num_cpus=4, configure_logging=False)
ds = ray.data.range(1000) # create a dataset from a range
ds # Dataset(num_rows=1000, schema={id: int64})
ds.count() # explicitly count the number of rows; might be expensive (to load the dataset into memory)
ds.take(3) # return first 3 rows as a list of dictionaries; default keys are often 'id' or 'item'
len(ds.take()) # default is 20 rows
ds.show(3) # first 3 rows in a different format (one row per line)
Until recently, you could easily displays the number of blocks in a dataset, but now you have to materialize it first, and the number of blocks can change during execution:
ds.materialize().num_blocks() # will show the number of blocks; might be expensive
Rows can be generated from arbitrary items:
ray.data.from_items([10,20,30]).take() # [{'item': 10}, {'item': 20}, {'item': 30}]
Rows can have multiple key-value pairs:
Recall: each row is a dictionary, and dictionaries can have multiple entries.
listOfDict = [{"col1": i, "col2": i ** 2} for i in range(1000)] # each dict contains 2 pairs
ds = ray.data.from_items(listOfDict)
ds.show(5)
A dataset can also be loaded from a file:
Note: this example works on my computer (
pyenv activate hpc-env), but not on the training cluster wherearrow/19.0.1was compiled without S3 support.
dd = ray.data.read_csv("s3://anonymous@air-example-data/iris.csv") # load a predefined dataset
dd
dd.show() # might pause to read data, default is 20 rows
Transforming datasets
Ray datasets become useful once you start processing them. Let’s initialize a simple dataset from a range:
import ray
ray.init(num_cpus=4, configure_logging=False)
ds = ray.data.range(1000) # create a dataset
ds.show(5)
We will apply a function to each row in this dataset. This function must return a dictionary that will form each row in the new dataset:
ds.map(lambda row: row).show(3) # takes a row, returns the same row
ds.map(lambda row: {"key": row["id"]}).show(3) # takes a row, returns a similar row;
# `row["id"]` is needed to refer to the value in each
# original row; `key` is a new, arbitrary key name
a = ds.map(lambda row: {"long": str(row["id"])*3}) # takes a row, returns a dict with 'id' values
# converted to strings and repeated 3X
a # it is a new dataset
a.show(5)
With .map() you can also use familiar non-lambda (i.e. non-anonymous) functions:
def squares(row):
return {'squares': row['id']**2}
ds.map(squares).show(5)
Your function can also add new key-value pairs to the existing rows, instead of returning brand new rows:
ds = ray.data.range(1000)
def addSquares(row):
row['square'] = row['id']**2 # add a new entry to each row
return row
b = ds.map(addSquares)
ds.show(5) # original dataset
b.show(5) # contains both the original entries and the squares
You might have already noticed by now that all processing in Ray Data is lazy, i.e. it happens when we request results:
ds = ray.data.range(10_000_000) # define a bigger dataset
ds.map(addSquares) # no visible calculation, just a request, not consuming results
ds.map(addSquares).show() # print results => start calculation
ds.map(addSquares).show() # previous results were not stored, so this will re-run the calculation
b = ds.map(addSquares) # this does not start calculation
b.show() # this starts calculation
Every time you print or use b, it’ll re-do the calculation. For this reason, you can think of b not as a
variable with a value but as a data stream.
How can you do the calculation once and store the results for repeated use? You can convert b into a more
permanent (not a data stream) object, e.g. a list:
b = ds.map(addSquares) # this does not start calculation
c = b.take() # create a list, fast (only first 20 elements)
c = b.take(10_000_000) # takes a couple of minutes, runs in parallel
This is not very efficient … certainly, computing 10,000,000 squares should not take a couple of minutes in parallel! The problem is that we have too many rows, and – similar to Python lists – Ray datasets perform poorly with too many rows. Think about subdividing your large computation into a number of chunks where each chunk comes with its own computational and communication overhead – you want to keep their number small.
Let’s rewrite this problem:
n = 10_000_000
n1 = n // 2
n2 = n - n1
from time import time
import numpy as np
ds = ray.data.from_items([np.arange(n1), n1 + np.arange(n2)])
ds.show() # 2 rows
def squares(row):
return {'squares': row['item']**2} # compute element-wise square of an array
start = time()
b = ds.map(squares).take()
end = time()
print("Time in seconds:", round(end-start,3))
print(b)
Now the runtime is 0.072 seconds.
Vectorizable dataset transformations
The function .map_batches() will process batches (blocks) of rows, vectorizing operations on NumPy arrays
inside each batch. We won’t study it here, as in practical terms it does not solve the specific problems in
this course any faster. With .map_batches() you are limited in terms of data types that you can use inside a
function passed to .map_batches() – in general it expects vectorizable NumPy arrays. If you are not
planning to vectorize via map_batches(), use map() instead, and you will still get parallelization.
Slow series with Ray Data
Let’s start with a serial implementation:
from time import time
import ray
ray.init(configure_logging=False)
intervals = ray.data.from_items([{"a": 1, "b": 100_000_000}]) # one item
intervals.show()
def slow(row):
total = 0
for i in range(row['a'], row['b']+1):
if not "9" in str(i):
total += 1.0 / i
row['sum'] = total # add key-value pair to the row
return row
start = time()
partial = intervals.map(slow) # define the calculation
total = partial.take()[0]['sum'] # request the result => start the calculation on 1 CPU core
end = time()
print("Time in seconds:", round(end-start,3))
print(total)
I get the average runtime of 6.978 seconds. To parallelize this, you can redefine intervals:
intervals = ray.data.from_items([
{"a": 1, "b": 50_000_000},
{"a": 50_000_001, "b": 100_000_000},
])
start = time()
partial = intervals.map(slow) # define the calculation
total = sum([p['sum'] for p in partial.take()]) # request the result => start the calculation on 2 CPU cores
end = time()
print("Time in seconds:", round(end-start,3)) # 4.322, 4.857, 4.782 and 3.852 3.812 3.823
print(total)
On 2 cores I get the average time of 3.765 seconds.
Question 14
Parallelize this for 4 CPU cores. Hint: programmatically form a list of dictionaries, each containing two key-value pairs (a and b) with the sub-intervals.
On my laptop I am getting:
| ncores | 1 | 2 | 4 | 8 |
| wallclock runtime (sec) | 6.978 | 3.765 | 1.675 | 1.574 |
Processing Ray datasets with Numba-compiled functions
So far we processed Ray datasets with non-Numba functions, either lambda (anonymous) or plain Python functions, and we obtained very good parallel scaling with multiple Ray processes. However, these functions are slower than their Numba-compiled versions.
Is it possible to process Ray datasets with Numba-compiled functions, similar to how earlier we executed Numba-compiled functions on remote workers? The answer is a firm yes, but I will leave it to you to write an implementation for the slow series problem. Even though I have the solution on my laptop, I am not providing it here, as I feel this would be an excellent take-home exercise.
A couple of considerations:
- Numba does not work with Python dictionaries, instead providing its own dictionary type which is not compatible with Ray datasets. You can easily sidestep this problem, but you will have to find the solution yourself.
- Very important: you must do small runs on workers to copy your functions over to them – no need to time these runs. Without this “pre-compilation” step you will not get fast execution on workers on the bigger problem the first time you run it.
With this Numba-compiled processing, on my laptop I am getting:
| ncores | 1 | 2 | 4 | 8 |
| wallclock runtime (sec) | 0.447 | 0.234 | 0.238 | 0.137 |
I am not quite sure why going 2 → 4 cores does not result in better runtimes, but there could be some inherent overhead in Ray tasks implementation on my laptop that shows up in this small problem – or more likely the efficiency cores enter the calculation at this time?
With the same code on the training cluster I get better scaling:
| ncores | 1 | 2 | 4 | 8 |
| wallclock runtime (sec) | 1.054 | 0.594 | 0.306 | 0.209 |
Running Ray workflows on a single node
Question 15
Let’s try running the slow series without Numba-compiled functions on the training cluster as a batch job.
- Save the entire Python code for the slow series problem into
rayPartialMap.py - Modify the code to take as a command-line argument:
import sys
ncores = int(sys.argv[1])
ray.init(num_cpus=ncores, configure_logging=False)
and test it from the command line inside your interactive job
python rayPartialMap.py $SLURM_CPUS_PER_TASK
- Quit the interactive job.
- Back on the login node, write a Slurm job submission script, in which you launch
rayPartialMap.pyin the last line of the script. - Submit your job with
sbatchto 1, 2, 4, 8 CPU cores, all on the same node.
Testing on the training cluster:
| ncores | 1 | 2 | 4 | 8 |
| wallclock runtime (sec) | 15.345 | 7.890 | 4.264 | 2.756 |
Testing on Cedar (averaged over 2 runs):
| ncores | 1 | 2 | 4 | 8 | 16 | 32 |
| wallclock runtime (sec) | 18.263 | 9.595 | 5.228 | 3.048 | 2.069 | 1.836 |
In our Ray documentation there are instructions for launching a
single-node Ray cluster. Strictly speaking, this is not necessary, as on a single machine (node) a call to
ray.init() will start a new Ray cluster and will automatically connect to it.
Running Ray workflows on multiple nodes
To run Ray workflows on multiple cluster nodes, you must create a virtual Ray cluster first. You can find details of Ray’s virtual clusters in the official Ray documentation https://docs.ray.io/en/latest/cluster/getting-started.html.
Here we’ll take a look at the example which I copied and adapted from our documentation at https://docs.alliancecan.ca/wiki/Ray#Multiple_Nodes. I made several changes in this workflow:
- made it interactive,
- not creating virtual environments in
$SLURM_TMPDIRinside the job, but using the already existing one in/project/def-sponsor00/shared/hpc-env, - removed GPUs.
Let’s quit our current Slurm job (if any), back on the login node start the following interactive job, and then run the following commands:
module load python/3.12.4 arrow/19.0.1 scipy-stack/2025a netcdf/4.9.2
source /project/def-sponsor00/shared/hpc-env/bin/activate
salloc --nodes 2 --ntasks-per-node=1 --cpus-per-task=2 --mem-per-cpu=3600 --time=0:60:0
export HEAD_NODE=$(hostname) # head node's address -- different from the login node!
export RAY_PORT=34567 # a port to start Ray on the head node
Next, we will start a Ray cluster on the head node as a background process:
ray start --head --node-ip-address=$HEAD_NODE --port=$RAY_PORT --num-cpus=$SLURM_CPUS_PER_TASK --block &
sleep 10 # wait for the prompt; it'll ask to enable usage stats collection
...
# Eventually should say "Ray runtime started."
Then on each node inside our Slurm job, except the head node, we launch the worker nodes of the Ray cluster:
cat << EOF > launchRay.sh
#!/bin/bash
module load python/3.12.4 arrow/19.0.1 scipy-stack/2025a netcdf/4.9.2
source /project/def-sponsor00/shared/hpc-env/bin/activate
if [[ "\$SLURM_PROCID" -eq "0" ]]; then # if MPI rank is 0
echo "Ray head node already started..."
sleep 10
else
ray start --address "${HEAD_NODE}:${RAY_PORT}" --num-cpus="${SLURM_CPUS_PER_TASK}" --block
sleep 5
echo "Ray worker started!"
fi
EOF
chmod u+x launchRay.sh
srun launchRay.sh &
ray_cluster_pid=$! # get its process ID
Next, we launch a Python script that connects to the Ray cluster, checks the nodes and all available CPUs:
import ray
import os
ray.init(address=f"{os.environ['HEAD_NODE']}:{os.environ['RAY_PORT']}",_node_ip_address=os.environ['HEAD_NODE'])
...
# Eventually should say "Connected to Ray cluster."
print("Nodes in the Ray cluster:", ray.nodes()) # should see two nodes with 'Alive' status
print(ray.available_resources()) # should see 4 CPUs and 2 nodes
Finally, from bash, we shut down the Ray worker nodes:
kill $ray_cluster_pid
and terminate the job.
Distributed data processing on Ray and I/O-bound workflows
Simple distributed dataset example
With multiple CPU cores available, run the following Python code line by line, while watching memory usage in
a separate window with htop --filter "ray::IDLE":
import numpy as np
import ray
ray.init(configure_logging=False, _system_config={ 'automatic_object_spilling_enabled':False })
# 1. hide Ray's copious logging output
# 2. start as many ray::IDLE process as the physical number of cores -- we'll use only two of them below
# 3. disable automatic object spilling to disk
b = ray.data.from_items([(800,800,800), (800,800,800)]) # 800**3 will take noticeable 3.81GB memory
b.show()
def initArray(row):
nx, ny, nz = row['item']
row['array'] = np.zeros((nx,ny,nz))
return row
c = b.map(initArray)
c.show()
We’ll see the two arrays being initialized in memory, on two processes, with a couple of GBs of memory
consumed per process. Ray writes (“spills”) objects to storage once they are no longer in use, as it tries to
minimize the total number of “materialized” (in-memory) blocks. On Linux and MacOS, the temporary spill folder
is /tmp/ray, but you can customize its location as described
here.
With the automatic object spilling to disk disabled (our second flag to ray.init() above), these arrays will
stay in memory.
With that flag removed, and hence with the usual automatic object spilling to disk, these array blocks will be automatically written to disk, and the memory usage goes back to zero after a fraction of a second. If next you try to access these arrays, e.g.
d = c.take()
type(d[0]['array']) # numpy.ndarray
d[0]['array'].shape # (800, 800, 800)
they will be loaded temporarily into memory, which you can monitor with htop --filter "ray::IDLE".
Pandas on Ray (Modin)
You can run many types of I/O workflows on top of Ray. One famous example is “Modin” (previously called Pandas on Ray) which is a drop-in replacement for Pandas on top of Ray. We won’t study here, but it will run all your pandas workflows, and you don’t need to modify your code, except importing the library, e.g.
import pandas as pd
data = pd.read_csv("filename.csv", <other flags>)
will become
import modin.pandas as pd
import ray
data = pd.read_csv("filename.csv", <other flags>)
Modin will run your workflows using Ray tasks on multiple cores, potentially speeding up large workflows. You can find more information at https://github.com/modin-project/modin
Similarly, many other Ray Data read functions will read your data in parallel, distributing it to multiple processes if necessary for larger processing:
>>> import ray
>>> ray.data.read_
ray.data.read_api ray.data.read_databricks_tables( ray.data.read_mongo( ray.data.read_sql(
ray.data.read_bigquery( ray.data.read_datasource( ray.data.read_numpy( ray.data.read_text(
ray.data.read_binary_files( ray.data.read_images( ray.data.read_parquet( ray.data.read_tfrecords(
ray.data.read_csv( ray.data.read_json( ray.data.read_parquet_bulk( ray.data.read_webdataset(
Processing images
Note: this example won’t work on the training cluster, where
arrow/14.0.1was compiled without proper filesystem support. However, I can demo this on my computer.
Here is a simple example of processing a directory with images with Ray Data. Suppose we have a $2874\times
2154$ image tuscany.avif. Let’s crop 100 random $300\times 300$ images out of it:
tmpdir=${RANDOM}${RANDOM}
mkdir -p ~/$tmpdir && cd ~/$tmpdir
pyenv activate hpc-env
wget https://wgpages.netlify.app/img/tuscany.jpg
ls -l tuscany.jpg
mkdir -p images
width=$(identify tuscany.jpg | awk '{print $3}' | awk -Fx '{print $1}')
height=$(identify tuscany.jpg | awk '{print $3}' | awk -Fx '{print $2}')
for num in $(seq -w 00 99); do # crop it into hundred 300x300 random images
echo $num
x=$(echo "scale=8; $RANDOM / 32767 * ($width-300)" | bc) # $RANDOM goes from 0 to 32767
x=$(echo $x | awk '{print int($1+0.5)}')
y=$(echo "scale=8; $RANDOM / 32767 * ($height-300)" | bc)
y=$(echo $y | awk '{print int($1+0.5)}')
convert tuscany.jpg -crop 300x300+$x+$y images/small$num.png
done
Now we will load these images into Ray Data. First, let’s set export RAY_DEDUP_LOGS=0, and then do:
import ray
ds = ray.data.read_images("images/")
ds # 100 rows (one image per row) split into ... blocks
ds.take(1)[0] # first image
type(ds.take(1)[0]["image"]) # stored as a numpy array
ds.take(1)[0]["image"].shape # 300x300 and three channels (RGB)
ds.take(1)[0]["image"].max() # 255 => they are stored as 8-bit images (0..255)
Let’s print min/max values for all images:
def minmax(row):
print(row["image"].min(), row["image"].max())
return row # must return a dictionary, otherwise `map` will fail
b = ds.map(minmax) # on output; we scheduled the calculation, but have not started it yet
b.materialize() # force the calculation => now we see printouts from individual rows
Let’s compute their negatives:
def negate(row):
return {'image': 255-row['image']}
negative = ds.map(negate)
negative.write_images("output", column='image')
In output/ subdirectory you will find 100 negative images.
Coding parallel I/O by hand
In Ray Data you can also write your own parallel I/O workflows by hand, defining functions to process rows that will load certain data/file into a specific row, e.g. with something like this:
a = ray.data.from_items([
{'file': '/path/to/file1'},
{'file': '/path/to/file2'},
{'file': '/path/to/file3'}
])
def readFileInParallel(row):
<load data from file row['file']>
<process these data>
row['status'] = 'done'
return row
b = a.map(readFileInParallel)
b.show()
A CPU-intensive problem without reduction
So far we’ve been working with problems where calculations from individual tasks add to form a single number (sum of a slow series) – this is called reduction. Let’s now look at a problem without reduction, i.e. where results stay distributed.
Let’s compute a mathematical Julia set defined as a set of points on the complex plane that remain bound under an infinite recursive transformation $z_{i+1}=f(z_i)$. For the recursive function, we will use the traditional form $f(z)=z^2+c$, where $c$ is a complex constant. Here is our algorithm:
- pick a point $z_0\in\mathbb{C}$
- compute iterations $z_{i+1}=z_i^2+c$ until $|z_i|>4$ (arbitrary fixed radius; here $c$ is a complex constant)
- store the iteration number $\xi(z_0)$ at which $z_i$ reaches the circle $|z|=4$
- limit max iterations at 255
4.1 if $\xi(z_0)\lt 255$, then $z_0$ is a stable point
4.2 the quicker a point diverges, the lower its $\xi(z_0)$ is - plot $\xi(z_0)$ for all $z_0$ in a rectangular region $-1.2<=\mathfrak{Re}(z_0)<=1.2$ and $-1.2<=\mathfrak{Im}(z_0)<=1.2$
We should get something conceptually similar to this figure (here $c = 0.355 + 0.355i$; we’ll get drastically different fractals for different values of $c$):
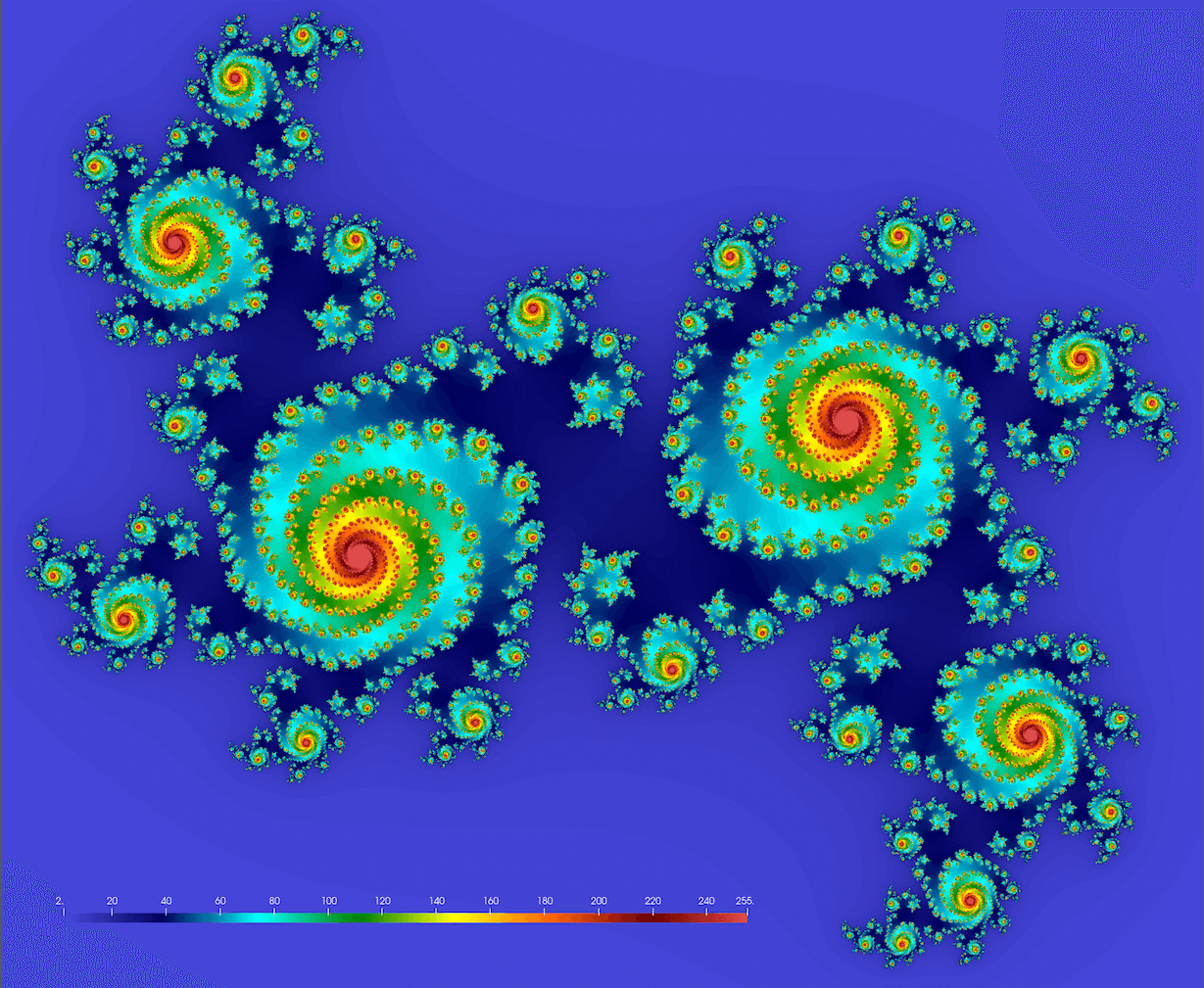
Note: you might want to try these values too:
- $c = 1.2e^{1.1πi}$ $~\Rightarrow~$ original textbook example
- $c = -0.4-0.59i$ and 1.5X zoom-out $~\Rightarrow~$ denser spirals
- $c = 1.34-0.45i$ and 1.8X zoom-out $~\Rightarrow~$ beans
- $c = 0.34-0.05i$ and 1.2X zoom-out $~\Rightarrow~$ connected spiral boots
As you must be accustomed by now, this calculation runs much faster when implemented in a compiled language. I tried Julia (0.676s) and Chapel (0.489s), in both cases running the code on my laptop in serial (one CPU core), both with exactly the same workflow and the same $2000^2$ image size.
Below is the serial implementation in Python – let’s save it as juliaSetSerial.py:
from time import time
import numpy as np
nx = ny = 2000 # image size
def pixel(z):
c = 0.355 + 0.355j
for i in range(1, 256):
z = z**2 + c
if abs(z) >= 4:
return i
return 255
print("Computing Julia set ...")
stability = np.zeros((nx,ny), dtype=np.int32)
start = time()
for i in range(nx):
for k in range(ny):
point = 1.2*((2*(i+0.5)/nx-1) + (2*(k+0.5)/ny-1)*1j) # rescale to -1.2:1.2 in the complex plane
stability[i,k] = pixel(point)
end = time()
print("Time in seconds:", round(end-start,3))
import netCDF4 as nc
f = nc.Dataset('test.nc', 'w', format='NETCDF4')
f.createDimension('x', nx)
f.createDimension('y', ny)
output = f.createVariable('stability', 'i4', ('x', 'y')) # 4-byte integer
output[:,:] = stability
f.close()
Here we are timing purely the computational part, not saving the image to a NetCDF file. Let’s run it and look at the result in ParaView! When running this on my laptop, it takes 9.220 seconds.
How would you parallelize this problem with ray.data? The main points to remember are:
- You need to subdivide your problem into blocks – let’s do this in the
ny(vertical) dimension. - You have to construct a dataset with each row containing inputs for a single task. These inputs will be the size of each image block and the offset (the starting row number of this block inside the image).
- You need to write a function
computeStability(row)that acts on each input row in the dataset. The result will be a NumPy array stored as a new entrystabilityin each row. - To write the final image to a NetCDF file, you need to merge these arrays into a single $2000\times 2000$ array, and then write this square array to disk.
The solution is in the file juliaSetParallel.py on instructor’s laptop. Here are the runtimes for
$2000\times 2000$ (averaged over three runs):
| ncores | 1 | 2 | 4 | 8 |
| wallclock runtime (sec) | 9.220 | 4.869 | 2.846 | 2.210 |
Quickly on parallel Python in ML frameworks (Marie)
Machine learning (ML) frameworks in Python usually come with their own parallelization tools, so you do not need to use general parallel libraries that we discussed in this course.
JAX
PyTorch
- PyTorch Distributed (torch.distributed) Overview
- Distributed and Parallel Training Tutorials
- Getting Started with DistributedDataParallel (DDP) module
- Using multiple GPUs with DataParallel